Abstract
Neural Radiance Fields (NeRF) methods have proved effective as compact, high-quality and versatile representations for 3D scense, and enable downstream tasks such as editing, retrieval, navigation, etc. Various neural architectures are vying for the core data structure of NeRF, including the plain Multi-Layer Perceptron (MLP), sparse tensors, low-rank tensors, hash tables and their compositions. Each of these representations has its particular set of trade-offs. For example, the hash table based representations admit faster training and rendering but their lack of clear geometric meaning hampers downstream tasks like spatial-relation-aware editing. In this paper, we propose Progressive Volume Distillation (PVD), a systematic distillation method that allows any-to-any conversions between different neural architectures, including MLP, sparse or low-rank tensors, hash tables and their compositions. PVD consequently empowers downstream applications to optimally adapt the neural representations for the task in hand in a post hoc fashion. The conversions are fast, as distillation is progressively performed on different levels of volume representations, from shallower to deeper. We also employ special treatment of density volume to deal with its specific numerical instability problem. Empirical evidences are presented to validate our method on the NeRF-Synthetic, LLFF and TanksAndTemples datasets. For example, with PVD, an MLP-based NeRF model can be distilled from a hash table-based Instant-NGP model at a 10X ~ 20X faster speed than being trained from scratch, while achieving superior level of sysnthesis quality.
Method
Our method aims to achieve mutual conversions between different architectures based on Radiance Fields. The architectures we have derived formula include implicit representations like MLP in NeRF, explicit representations like sparse tensors in Plenoxels, and two hybrid representations: hash tables (in INGP) and low-rank tensors (VM-decomposition in TensoRF). Once formulated, any-to-any conversion between these architectures and their compositions is possible using PVD.
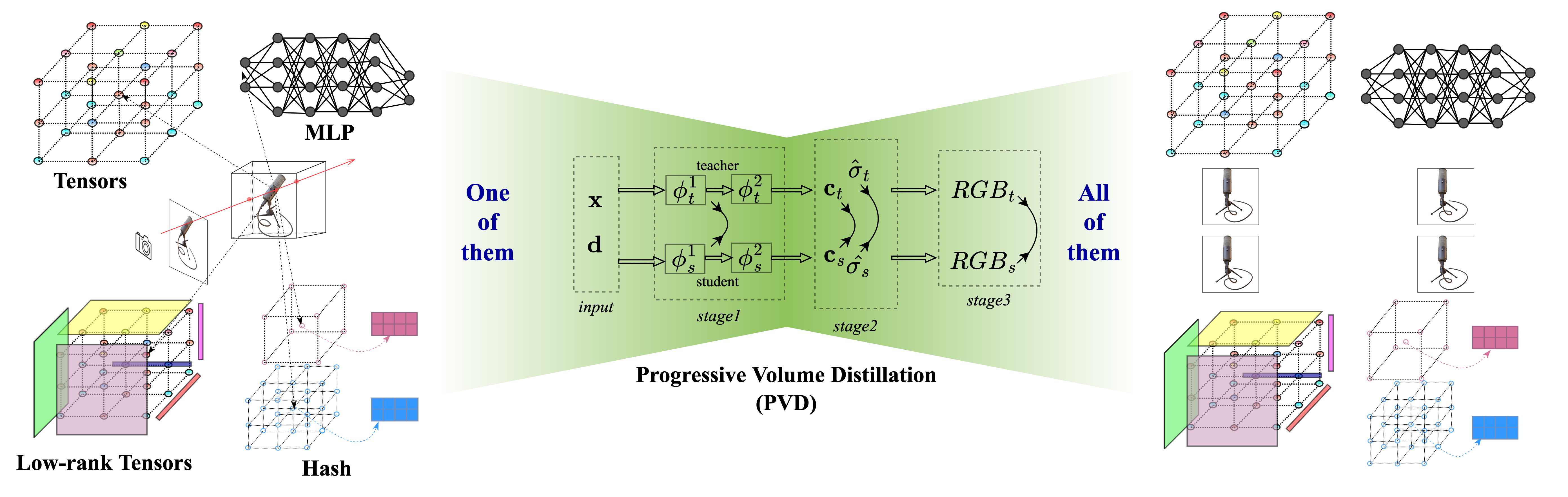
Loss on intermediate volume representations (shown as double arrow symbol) like output of φ, color and constrained density are used alongside the final rendered RGB volume to accelerate the distillation.
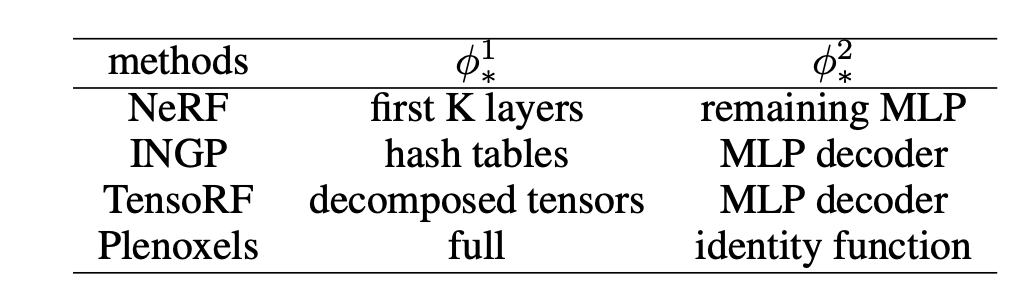
We observed that the implicit and explicit structures in the hybrid representation are naturally separated and correspond to different learning objectives. Therefore, we consider splitting a model into this similar expression forms so that different parts can be aligned during distillation just like descripted in the table above.
Video Display
Mutual-Conversion - lego
Erasing the bucket by editing Tensors(Plenoxels) and distilling back to MLP(NeRF) - lego
VM2others - LLFF
Hash2others - TanksAndTemples
BibTeX
@article{pvd2023,
author = {Fang, Shuangkang and Xu, Weixin and Wang, Heng and Yang, Yi and Wang, Yufeng and Zhou, Shuchang},
title = {One is All: Bridging the Gap Between Neural Radiance Fields Architectures with Progressive Volume Distillation},
journal = {AAAI},
year = {2023}
}